Tune hyperparameters with sweeps
5 minute read
W&B Sweeps optimize machine learning models by exploring combinations of hyperparameters, such as learning rate, batch size, hidden layer count, and optimizer type, to efficiently achieve metrics.
This guide shows how to create a hyperparameter search using the W&B PyTorch integration. Follow along with this video tutorial or this Google Colab notebook.
Sweeps: An overview
Running a hyperparameter sweep with Weights & Biases involves three steps:
- Define the sweep: Create a dictionary or a YAML file that specifies parameters to search, strategy, and optimization metrics.
- Initialize the sweep: Use
sweep_id = wandb.sweep(sweep_config)to initialize the sweep. - Run the sweep: Call
wandb.agent(sweep_id, function=train)to run the sweep and pass a function that defines and trains your model.
Before you begin
Obtain an API key at http://wandb.ai/authorize and save it as an environment variable under the key WANDB_API_KEY:
export WANDB_API_KEY={Your API Key}
Install the W&B Python SDK in your environment using pip:
pip install wandb
Log in to W&B, either via the shell with wandb login or in your Python script by importing wandb and calling wandb.login():
import wandb
wandb.login()
Step 1: define a sweep
W&B Sweeps combine a strategy for trying different hyperparameter values with evaluation code. Define your sweep strategy with a sweep configuration.
Pick a search method
Specify a hyperparameter search method in your configuration dictionary. Choose from grid, random, and Bayesian search.
Use random search for this tutorial:
sweep_config = {'method': 'random'}
Specify a metric for optimization. While not required for random search methods, tracking your sweep goals is important:
metric = {'name': 'loss', 'goal': 'minimize'}
sweep_config['metric'] = metric
Specify hyperparameters to search
Define which hyperparameters to search over by adding them to parameters_dict in your sweep configuration:
parameters_dict = {
'optimizer': {'values': ['adam', 'sgd']},
'fc_layer_size': {'values': [128, 256, 512]},
'dropout': {'values': [0.3, 0.4, 0.5]},
}
sweep_config['parameters'] = parameters_dict
To track a hyperparameter without varying it, specify its exact value:
parameters_dict.update({'epochs': {'value': 1}})
For a random search, all parameter values have an equal probability of selection.
Optionally, specify a distribution for parameters:
parameters_dict.update({
'learning_rate': {
'distribution': 'uniform',
'min': 0,
'max': 0.1,
},
'batch_size': {
'distribution': 'q_log_uniform_values',
'q': 8,
'min': 32,
'max': 256,
}
})
After defining sweep_config, print it to review:
import pprint
pprint.pprint(sweep_config)
For all configuration options, see Sweep configuration options.
values. For example, the preceding sweep configuration has a list of finite values specified for the layer_size and dropout parameter keys.Step 2: initialize the sweep
After defining your strategy, set up your implementation. W&B manages sweeps with a Sweep Controller, either cloud-based or local. This tutorial uses a cloud-managed sweep controller.
Activate the controller within your notebook using the wandb.sweep method with your sweep_config:
sweep_id = wandb.sweep(sweep_config, project="pytorch-sweeps-demo")
The wandb.sweep method returns a sweep_id to activate your sweep.
To run this function from the command line, use:
wandb sweep config.yaml
For terminal instructions, see the W&B Sweep walkthrough.
Step 3: define your machine learning code
Define a training procedure that accesses the hyperparameter values from the sweep configuration before running the sweep. The helper functions build_dataset, build_network, build_optimizer, and train_epoch use this configuration.
The following PyTorch training code defines a basic fully connected neural network:
import torch
import torch.optim as optim
import torch.nn.functional as F
import torch.nn as nn
from torchvision import datasets, transforms
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def train(config=None):
# Initialize a new wandb run
with wandb.init(config=config):
# If called by wandb.agent, this config is set by the Sweep Controller
config = wandb.config
loader = build_dataset(config.batch_size)
network = build_network(config.fc_layer_size, config.dropout)
optimizer = build_optimizer(network, config.optimizer, config.learning_rate)
for epoch in range(config.epochs):
avg_loss = train_epoch(network, loader, optimizer)
wandb.log({"loss": avg_loss, "epoch": epoch})
This example uses these W&B Python SDK methods within the train function:
wandb.init(): Initializes a new W&B run.wandb.config: Passes the sweep configuration.wandb.log(): Logs training loss for each epoch.
The next cell defines functions typical in a PyTorch pipeline, unaffected by W&B use:
def build_dataset(batch_size):
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])
# Download MNIST training dataset
dataset = datasets.MNIST(".", train=True, download=True,
transform=transform)
sub_dataset = torch.utils.data.Subset(
dataset, indices=range(0, len(dataset), 5))
loader = torch.utils.data.DataLoader(sub_dataset, batch_size=batch_size)
return loader
def build_network(fc_layer_size, dropout):
network = nn.Sequential( # Fully connected, single hidden layer
nn.Flatten(),
nn.Linear(784, fc_layer_size), nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(fc_layer_size, 10),
nn.LogSoftmax(dim=1))
return network.to(device)
def build_optimizer(network, optimizer, learning_rate):
if optimizer == "sgd":
optimizer = optim.SGD(network.parameters(),
lr=learning_rate, momentum=0.9)
elif optimizer == "adam":
optimizer = optim.Adam(network.parameters(),
lr=learning_rate)
return optimizer
def train_epoch(network, loader, optimizer):
cumu_loss = 0
for _, (data, target) in enumerate(loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# ➡ Forward pass
loss = F.nll_loss(network(data), target)
cumu_loss += loss.item()
# ⬅ Backward pass + weight update
loss.backward()
optimizer.step()
wandb.log({"batch loss": loss.item()})
return cumu_loss / len(loader)
For a complete guide on using W&B with PyTorch, visit this Colab.
Step 4: activate sweep agents
With your sweep configuration and training script ready, activate a sweep agent. Sweep agents run experiments using the hyperparameter values from your configuration.
Use the wandb.agent method to create agents. Provide:
- The sweep (
sweep_id) the agent belongs to. - The function for the sweep to run (for example,
train). - Optionally, how many configs to request from the sweep controller (
count).
sweep_id across different resources. The controller ensures collaborative functioning per configuration.The following cell initiates an agent running train 5 times:
wandb.agent(sweep_id, train, count=5)
random search method.For more information, view the W&B Sweep walkthrough.
Visualize sweep results
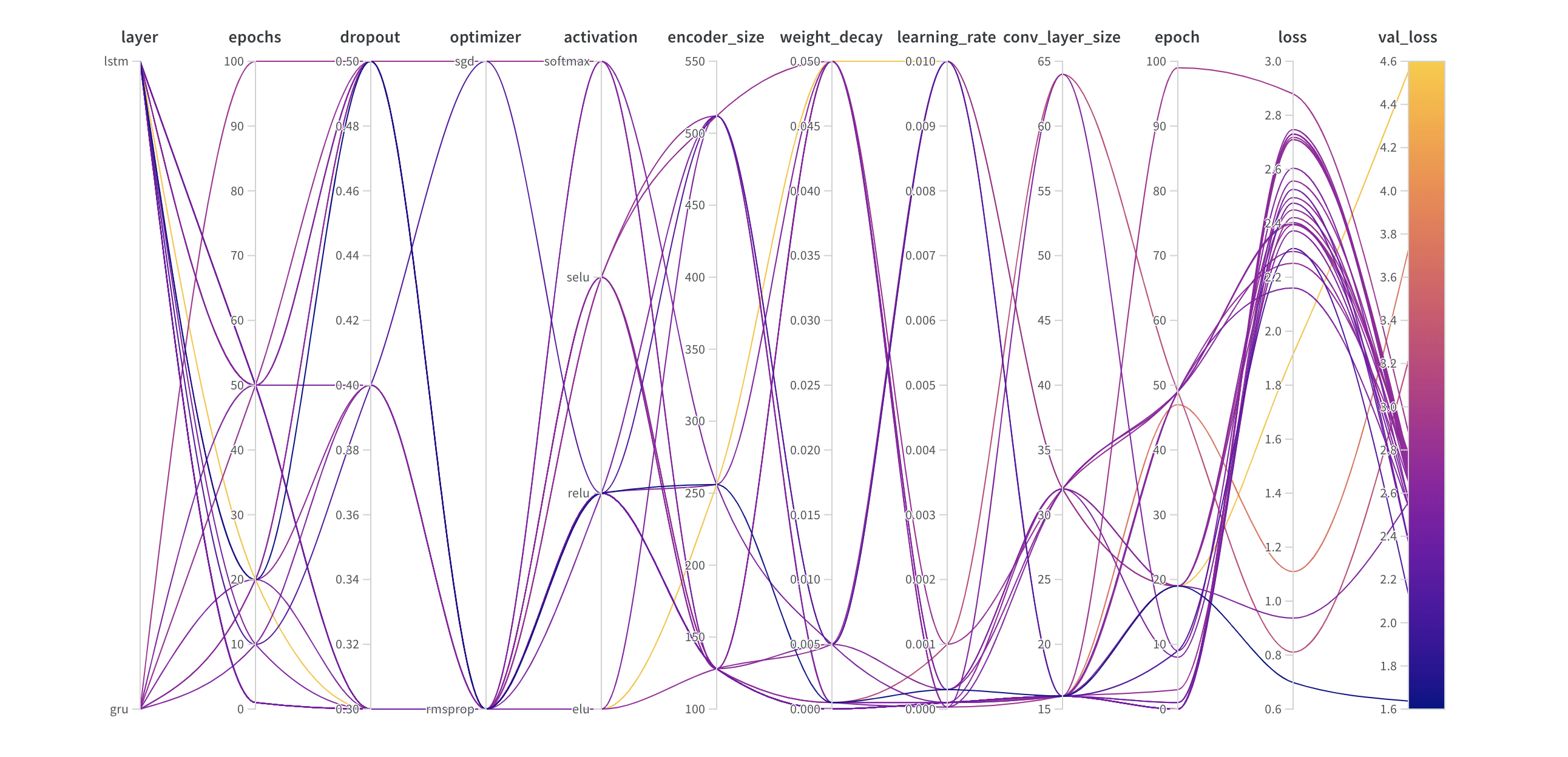
Parallel coordinates plot
This visualization maps hyperparameter values to model metrics and identifies effective hyperparameter combinations.
Hyperparameter importance plot
This visualization highlights hyperparameters that best predict metrics, displaying feature importance and correlation.
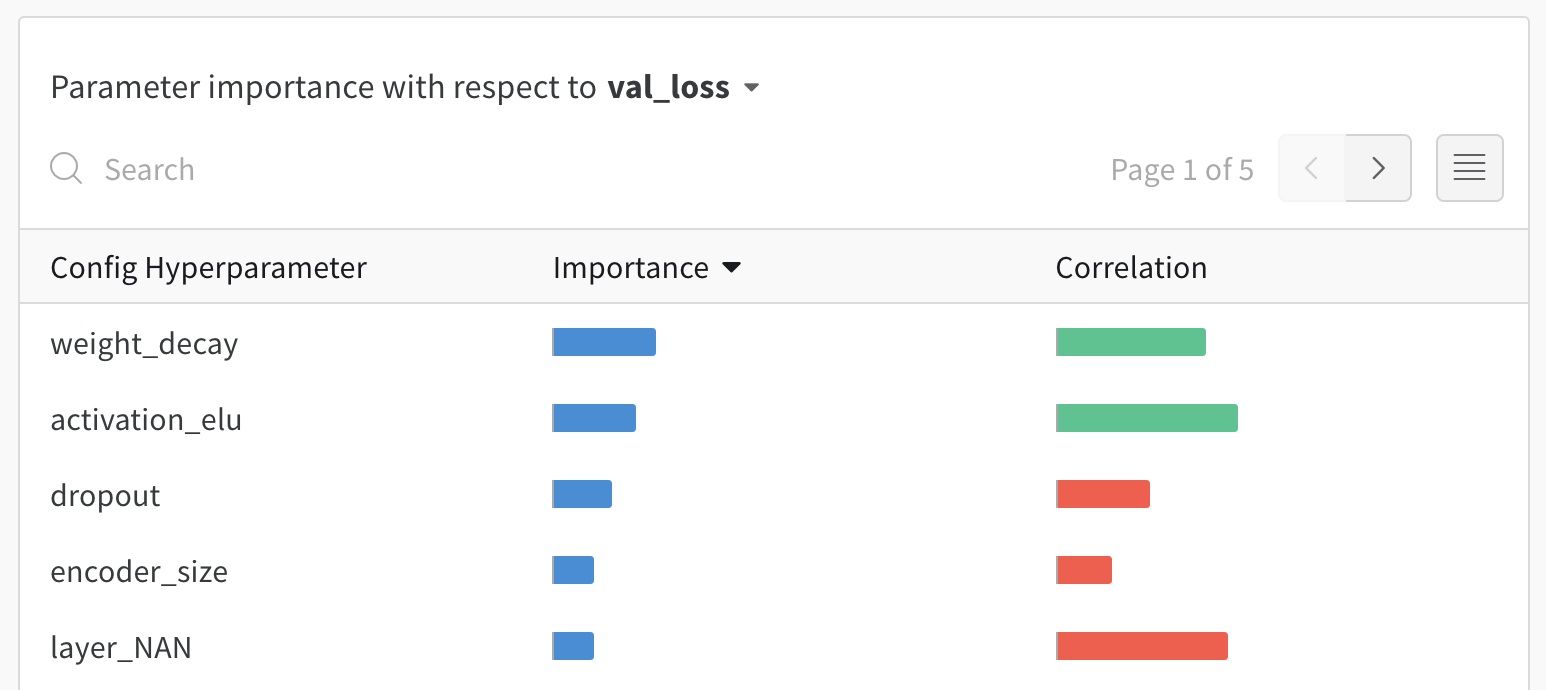
These visualizations identify crucial parameters and aid resource savings during hyperparameter optimizations.
Learn more about W&B sweeps
Explore a training script and various sweep configurations.
Find more examples showcasing advanced features like Bayesian Hyperband and Hyperopt.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.